This page is the public project page and will be updated every week.
Project Description
There are many infoboxes on wikipedia. Here is a example about football box:

As seen, every infobox has some properties. Actually, every infobox follows a certain template. In my project, the goal is to find mappings between the classes (eg. dbo:Person, dbo:City) in the DBpedia ontology and infobox templates on pages of Wikipedia resources using techniques of machine learning.
There are lots of infobox mappings available for a few languages, but not as many for other languages. In order to infer mappings for all the languages, cross-lingual knowledge validation should also be considered.
The main output of the project will be a list of new high-quality infobox-class mappings.
Weekly Progess
Week 1 (5.8-5.14)
- First meeting with my mentor
- Create the public page for the project
- Create the google doc for the project
Week 2 (5.15-5.21)
- Get the existing mappings
- Get the information about all templates: https://github.com/dbpedia/extraction-framework/tree/master/server/src/main/statistics
- Parse and clean the data
Week 3 (5.22-5.28)
- Figure out the information we have:
- 1) Existing mappings, we have manual information that a template in lang $X$ is mapped to class $Y$
- 2) Inter-language links between templates, e.g. template $X_1$ in lang $X$ is mapped to class $Y$ and there is a link from this template to templates in other languages. This gives a high probability that the equivalent templates in other languages should be mapped to the same class $Y$.
- 3) Links between articles in different languages and templates each article uses, this way, when (2) is not always true we can find which templates are used for the same concepts.
- 4) Most wikidata articles have a type assigned, using this information we have a variation of metric (3) but with manual types assigned.
- Process the information (1) - (3) described above and obtain some prelimenary results.
Week 4 (5.29-6.4)
- Propose a baseline approach: Given a template classified as an infobox, the approach is instance-based and exploits the already mapped articles and their cross-language links to the articles that contain the template to be mapped. This approach is summaried in the below figure.
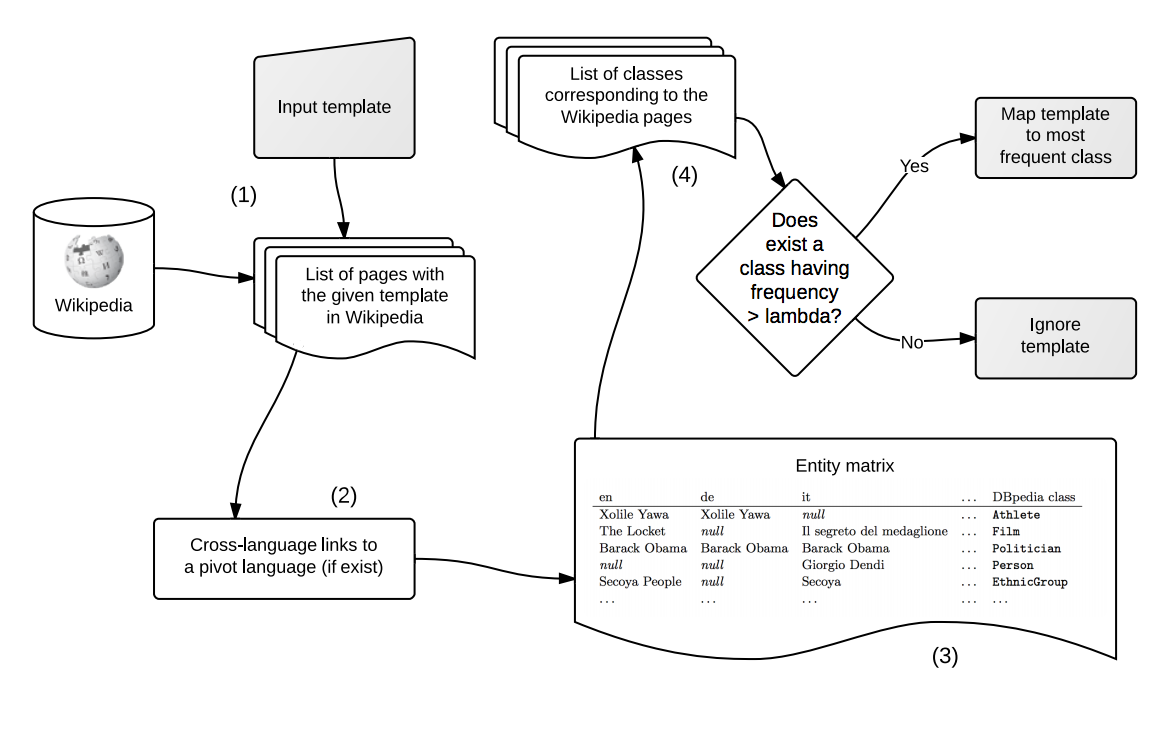
- Experiments:
- Based on existing mappings in English, to create mappings for Chinese.
- Evaluations: try this approach on some other languages which have some existing mappings. (In progress)
Week 5 (6.5-6.11)
- Learn the difference between infoboxes and macro templates and try to filter the macro templates.
- More experiments.
- Start to write a summary about the progress so far.
Week 6 (6.12-6.18)
- Complete the code and the documentation, see this repo on github.
- Complete the report about the current progress and further work required by the mid-term evaluation.
- Starts working on ontology hierarchy and templates filtering.
Week 7 (6.19-6.25)
- Use multiple languages to evaluate the predicted results.
- Use ontology hierarchy to assign types to articles and evaluate the predicted results.
Week 8 (6.26-7.2)
- Complete a script combining all the modules so far together, which can download the data, parse the data, predicted the mappings and evaluate on the predicted results as a whole.
- Update the README file and added some figures about the evaluation results on Bulgarian.
Week 9 (7.3-7.9)
- Use information in wikidata: Quite a bit entities in wikidata has a DBpedia ontology types assigned already. In addition, we have links between wikidata and other languages. As a result, we can treat wikidata as a pivot language directly. The information from wikidata can be useful to improve the performance of our approach.
- Case study on miss classified cases on Bulgarian.
Week 10 (7.10-7.16)
- Read papers for further improvements:
- Start working on manually checking the predicted mappings in Chinese as final output of the project.
Week 11 (7.17-7.23)
- Implement the ideas in this paper on DBpedia.
- Use cross-validation to evaluate the performance on link prediction task.
Week 12 (7.24-7.30)
- More experiments about tensor factorization on DBpedia. But the results are not that good.
Week 13 (7.31-8.6)
- Read papers about graph embeddings and applications on knowledge base: TransE and HOLE
- Apply the ideas in above paper on DBpedia. However, the results are still not that good compared to the results presented in the paper.
- Use grid search to find the optimal parameter setting to improve the performance.
Week 14 (8.7-8.13)
- For RESCAL, with large rank, it can achieve fairly good performance for tasks like type prediction on small languages like Balgarian. The AUC-PR is around 0.8. However, due to the memory limit, RESCAL performs poorly on larger languages like German and English.
- Develop two scripts based on RESCAL and HOLE to compute a score for given triples indicating the likelihood of the existance of the triples in DBpedia, which can help determine whether to add new triples to DBpedia.
- So far, I almost complete all my work for this project.
Week 15 (8.14-8.19)
- Submit the code and complete the final evaluations.