Policy Evaluation
Consider a sequence of approximate value functions $v_0, v_1, v_2, \dots,$ each mapping $\mathcal{S}^+$ to $\mathbb{R}$. The initial approximation, $v_0$ is chosen arbitrarily, and each successive approximation is obtained by using the Bellman equation for $v_\pi$ as an update rule:
for all $s\in\mathcal{S}$.

Policy Improvement
Let $\pi$ and $\pi’$ be any pair of deterministic policies such that, for all $s\in\mathcal{S}$,
Then the policy $\pi’$ must be as good as, or better than, $\pi$. That is, it must obtain greater or equal expected return from all states $s\in\mathcal{S}$:
This result is called policy improvement theorem.
Consider the new greedy policy, $\pi’$, given by
The greedy policy takes the action that looks best in the short term according to $v_\pi$. By construction, the greedy policy meets the conditions of the policy improvement theorem. The process of making a new policy that improves on an original policy, by making it greedy with respect to the value function of the original policy, is called policy improvement.
In addition, policy improvement must give us a strictly better policy excepy when the original policy is already optimal.
Policy Iteration

Value Iteration

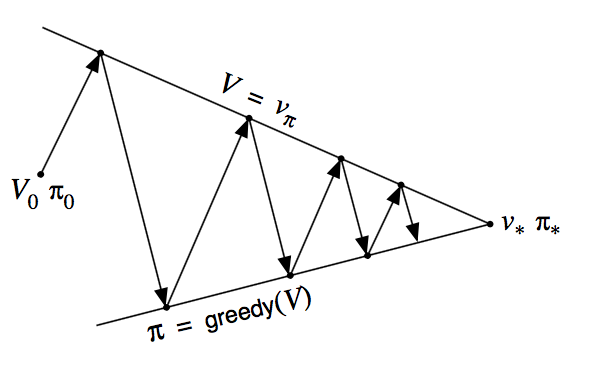
Generalized Policy Iteration
We use the term generalized policy iteration (GPI) to refer to the general idea of letting policy evaluation and policy improvement processes interact, independent of the grandularity and other details of the two processes.